AAAI Workshop 2026
Oral Presentation
Next-Frame Prediction as a Reliability-Aware Training Paradigm for Robust Vision Encoders
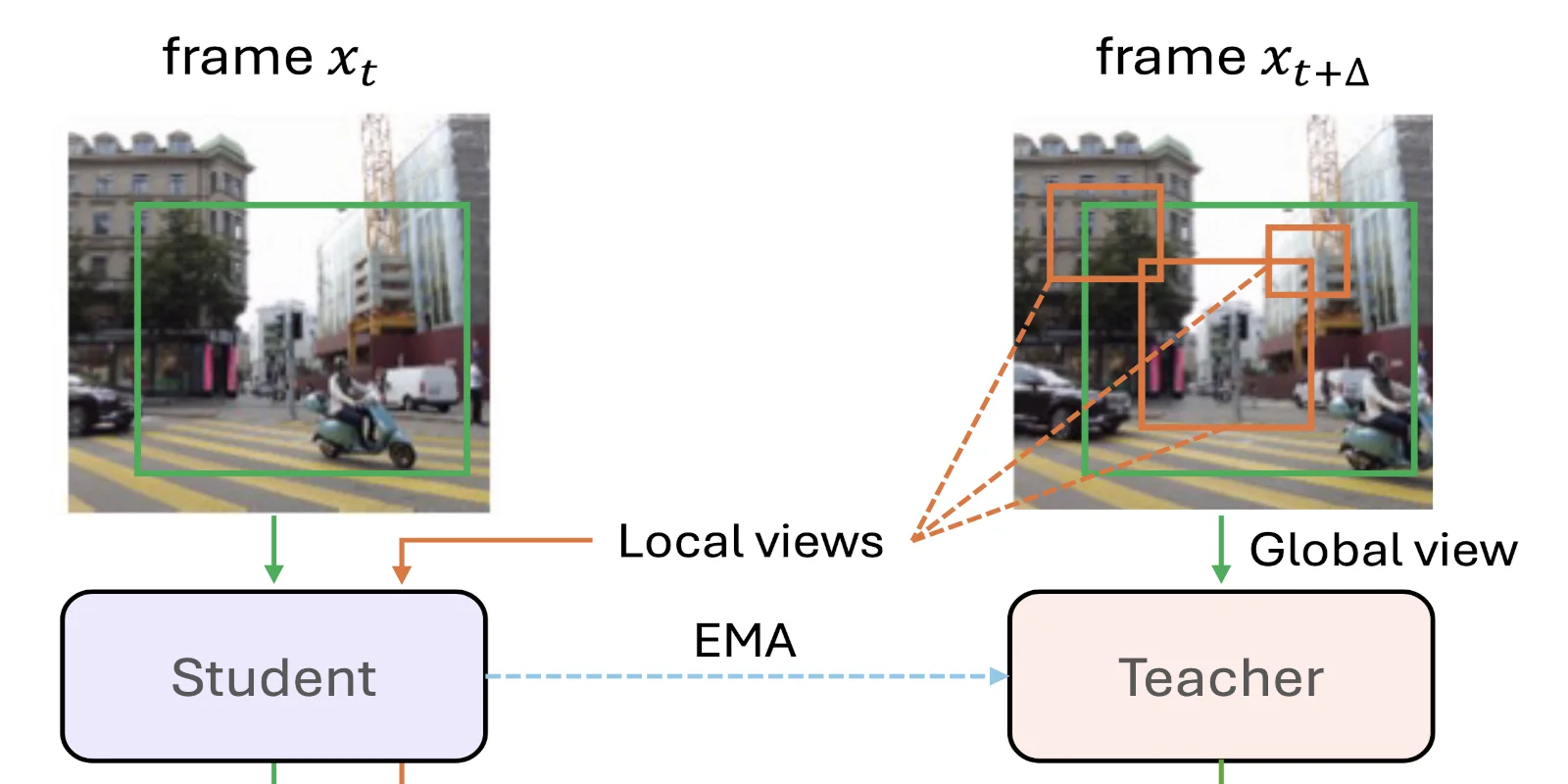
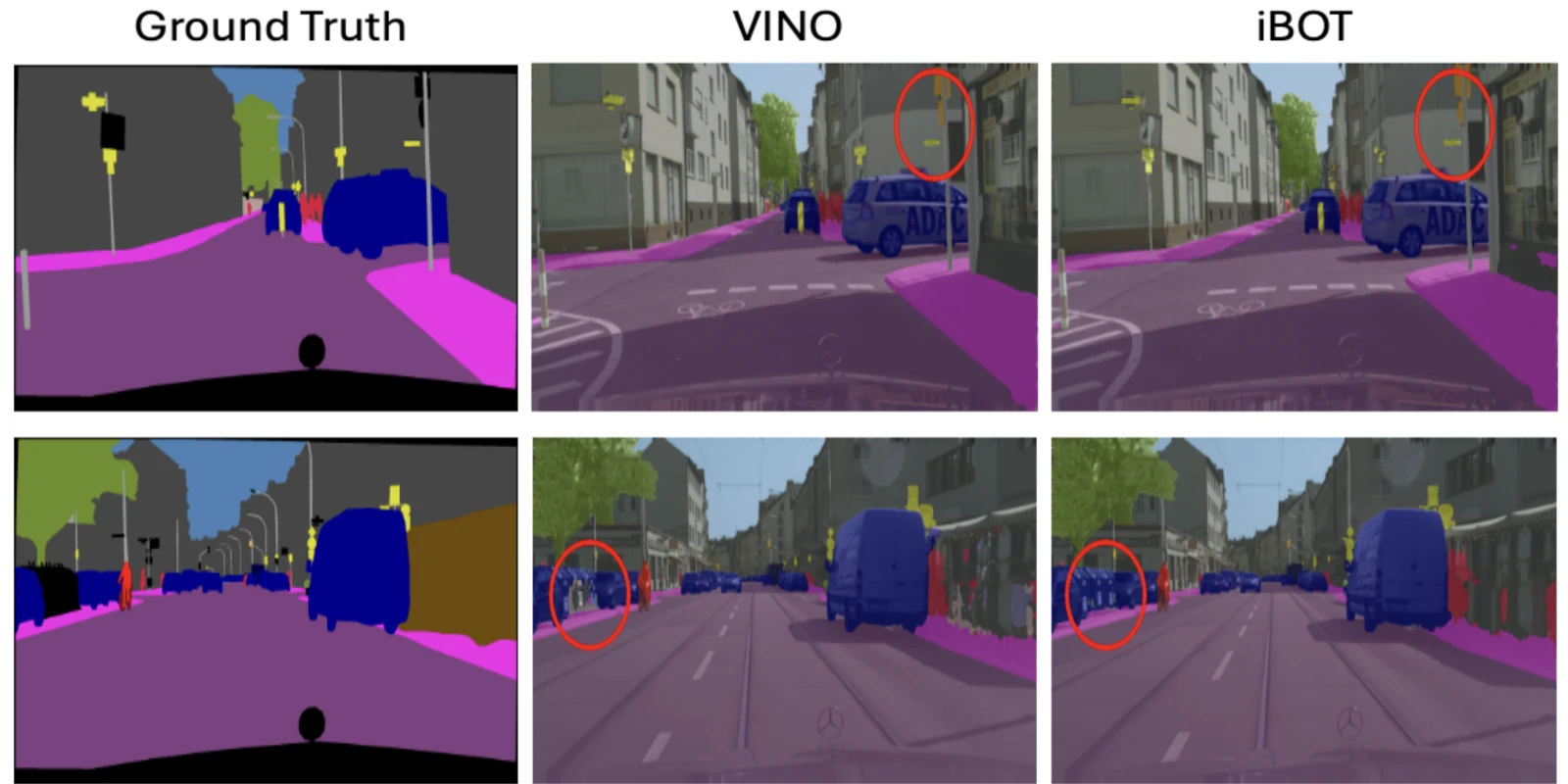
Foundation models deployed in dynamic domains suffer from critical reliability failures. We propose a lightweight paradigm that distills temporal knowledge from video into a standard single-image encoder, setting a new SOTA for DINO-style video distillation.
Read Abstract / Paper